Event report
Next Wisdom Gathering “人工知能の未来“ 【前編】増殖するテクノロジー
SHARE
ARTICLES
SHARE

ホーキング博士は、人工知能の進化に人類が歩調を合わせることができる能力を、人工知能が上回ることになる、いわゆる「技術的特異点(シンギュラリティー)」について懸念を表明したが、現状の人工知能研究はどういう局面にあるのか、そしてこれからどうなっていくのか。98年以降には、身体性の知覚、進化ロボットの研究を展開している池上氏をゲストに、人の進化と未来像について語らいました。
ゲスト:池上高志氏
複雑系の科学者。小中高と名古屋で過ごし、1984年東京大学理学部物理学科卒業。1989年同学大学院理学系研究科博士課程修了。現在は東京大学大学院総合文化研究科 広域科学専攻 広域システム科学系教授として教鞭を執る傍ら、複雑系科学研究者として、アートとサイエンスの領域を繋ぐ活動も精力的に行う。著書:『生命のサンドウィッチ理論』(講談社、2012)、『動きが生命をつくる―生命と意識への構成論的アプローチ』(青土社2007)など。
今日のテーマは人工知能(AI)ですが、僕の専門は物理学で、複雑系の科学をずっと研究していました。いわゆるAIとは少し分野が違いますが、学問の分野というのも文科省によって50年くらい前に決められたもので、いまは非常に境界が曖昧になっており、コンピュータサイエンス、生物学、物理学が重なってきています。
これはバクテリアの増殖ですが、これはエクスポネンシャル・グロース(exponential growth)と呼ばれています。分裂によって1匹が2匹になって、2匹が4匹になって、4匹が8匹になってと倍々に増えていくと、すごい数になる。これをエクスポネンシャル・グロースと言います。
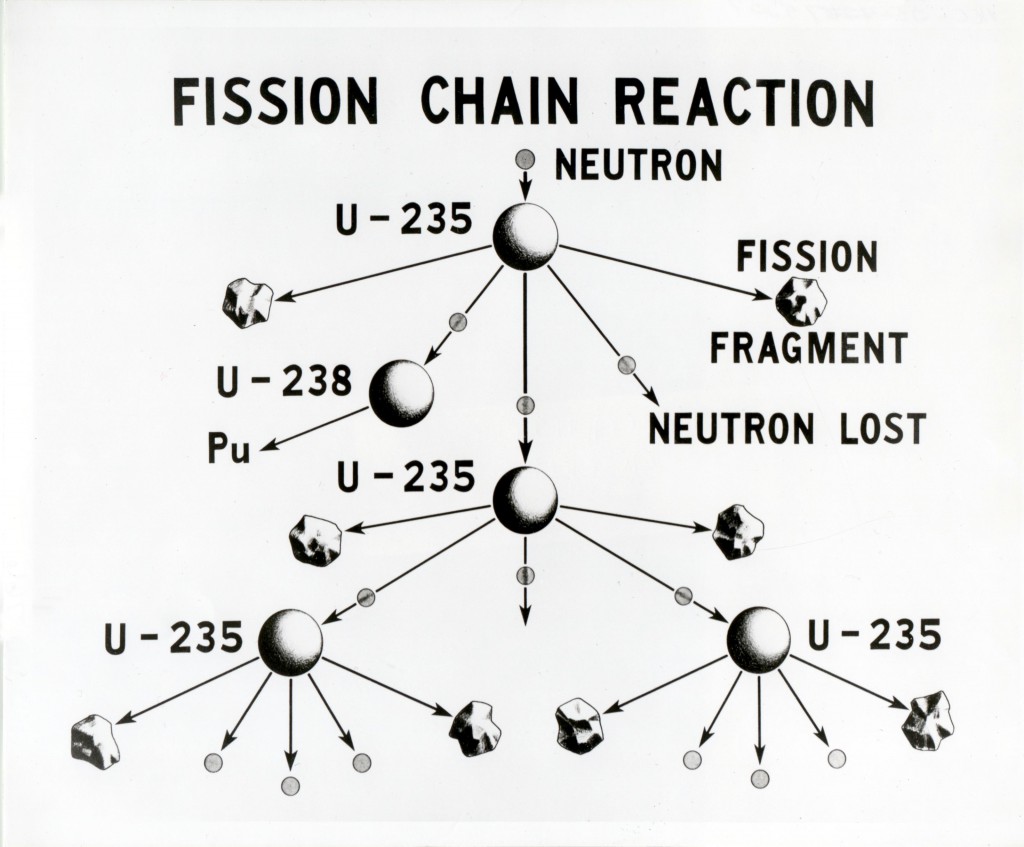
別の例は核分裂です。中性子が1個、ウラン235に当たると、それが二つに分裂します。このときに中性子が1個だったら、急に増えることはありません。しかし実際には中性子が2個や3個出るので、次々と連鎖的に増えていく。すると、あっという間に爆発が大きくなる。この現象を「核分裂の連鎖反応」とか「チェーン・リアクション」といって、爆発的に反応が進んでしまいます。
ウラン235の場合は22kgのウランがあると、連鎖反応が起こって核爆発が起こる。連鎖反応が起こるか起きないかギリギリの質量を「臨界質量」と呼びますが、二つのウラン235をくっつけてちょうど22kgになると、連鎖反応が始まって爆発する。これが広島や長崎に落とされた原子爆弾です。
このように、バクテリアの増殖やウラン235の連鎖反応に共通しているのが、指数関数的な増殖、英語で言うと「エクスポネンシャル・グロース」、日本語で言うと「指数関数的な増殖」と言います。
指数関数的な増殖
このエクスポネンシャル・グロースは科学の様々な分野で現れて、理論物理でも化学でも生物でも、ありとあらゆるところに指数関数的な増殖というものがあります。
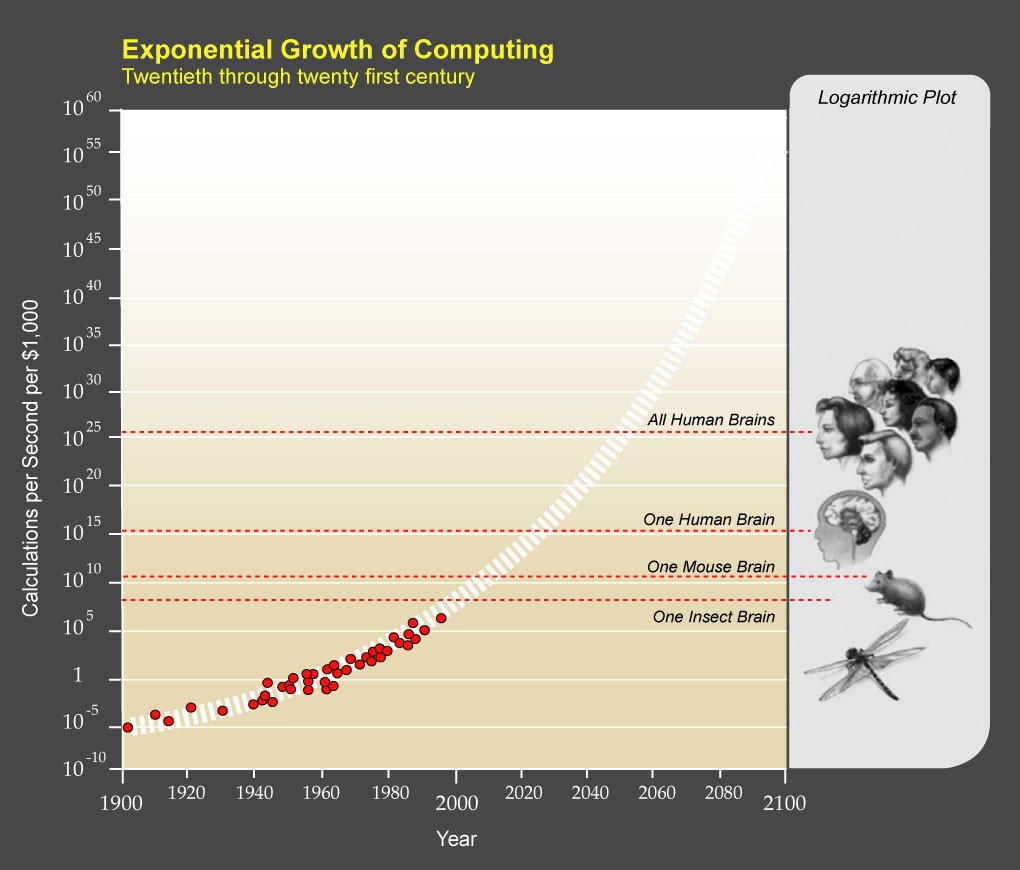
レイ・カーツワイルRay Kurzweilという発明家・未来学者が2004年に『The Singularity is Near』シンギュラリティは近い―人類が生命を超越するとき-レイ・カーツワイル-いう本を書きました。その中で「特異点が近い」ということを示して、世界的に話題になりました。この図は、技術的な革新度合いを縦軸に、横軸に年代を取っています。これのグラフが先ほどの「エクスポネンシャル・グロース」のカーブを描いている。技術革新が指数関数的な増殖を起こしていて、今から30年後の2045年にちょうど人の脳の計算能力を超えるまでに発散してしまう。そこで何が起こるのか、ということがSingularity(シンギュラリティ)問題です。その2045年という特異点で、今までの人生観や人の生き方というものを完全に書き換えるようなことが起こるだろうと考えられるわけです。その変化を担うのが今日のテーマである人工知能がメインである、というのが彼の考えです。
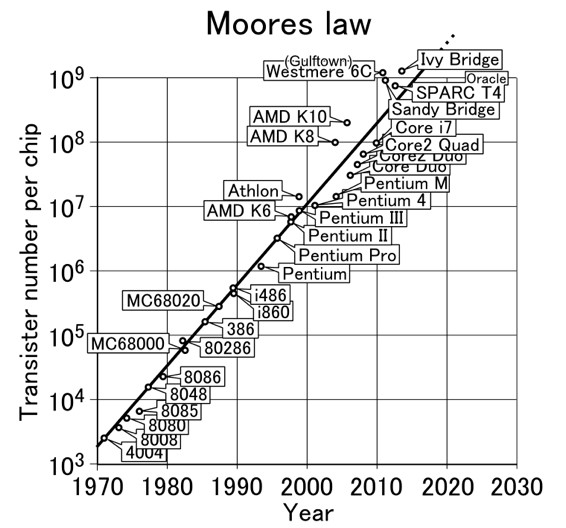
その例としてよく知られているのは「ムーアの法則」です。コンピュータの処理速度は1970年に比べて2010年は、桁数で4、一万倍速くなっています。僕の学生時代にPC-9801というNECのコンピュータが出て、そのときのプロセッサっていうのがIntel 8088でした。当時何十万もしたコンピュータの一万倍も速いコンピュータが、3分の1から4分の1の値段で買えるようになりました。当時のスーパーコンピュータは僕が使っているノートブックの千分の一の能力しかないわけです。当時はこんなことになるとは、みんな思ってもいなかった。これが「エクスポネンシャル・グロース」の威力です。

イギリス人数学者チャールズ・ バベッジが1822年に「階差エンジン」というコンピュータの原型を発明しました。当時使われていた織り機にヒントを得て、糸を歯車で織って布をつくるのではなく、数字を織って足し算、引き算、かけ算、わり算などいろんな計算ができるようにしました。この階差エンジンから始まって、爆発的にコンピュータのエクスポネンシャル・グロースが発散していきます。
ちょうど今『イミテーション・ゲーム』という映画が始まりました。すごく尊敬しているアラン・チューリングという数学者が主人公なのですが、バベッジの考えたコンピュータの上で理論をつくって「計算」というものを形式化した人です。1936年に彼が20歳くらいのときに「計算できない数」について論文を書きました。計算できない数を考えるためには、計算できる数を定義しなければなりません。その計算できる数をチューリング・マシンという形式でつくったのです。そして、それをいま実行しているのがこのMacBookでもあります。現代のコンピュータは全てアラン・チューリングのもとに生まれたと言ってもよいのですが、その前にバベッジが原型をつくり、それを理論的に証明したのがアラン・チューリングだと僕は思っています。
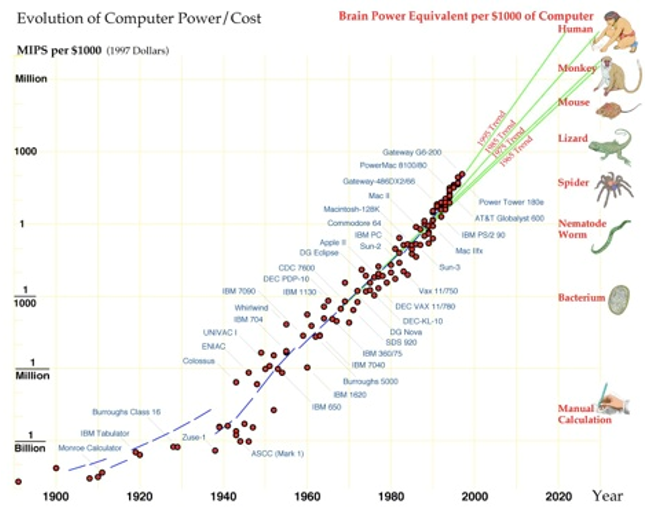
1900年、20年、40年、60年っていうのを横軸にとって、縦軸に1秒間に計算できる命令の数を3桁ずつとります。そこで直線になるグラフが指数関数的な増殖です。これを見ると1秒間に計算できる命令の数が指数関数的に増殖しています。コンピュータのパワーは1900年には10億分の1、それがいまは100万×10億倍です。ものすごい速さで計算が実行できるようになっています。人間の計算速度にコンピュータが到達するのが2045年、人間をはるかに超えた計算機が出現すると思われています。
コンピュータに代表されるように、現代の文明は、2が4で、4が8になり、8が16になり、16が32になるというエクスポネンシャル・グロースがベースになって動いています。これはまるで、我々は動きを変えられないまま、急流に流される葉っぱの上に乗っているアリのようなものです。嫌だといっても降りることはできない、それがシンギュラリティに向かっていくということです。それは制御できません。
生成的生物学 (Synthetic Biology)

Spiber(スパイバー)という蜘蛛の糸を人工的につくる日本のベンチャーがあります。そこで働いていた院生がうちの研究室に来たときに、何をしていたのかを聞いてみると、コンピュータでプログラミングをしていたというんです。プログラミングの技術がDNAを書き換えることにつながり、その先に人工的に合成された蜘蛛の糸がある。つまり、DNA分子を書き換えることとプログラムを書き換えることの差が無くなってきているということ、それが生成的生物学です。生物学は既にコンピュータと同じレベルのスピードで発達していて、化学と生物学の境界が揺らいでいます。生成的生物学というのも指数関数的に増殖した生物学だといえます。
増殖するインターネット・ウェブ
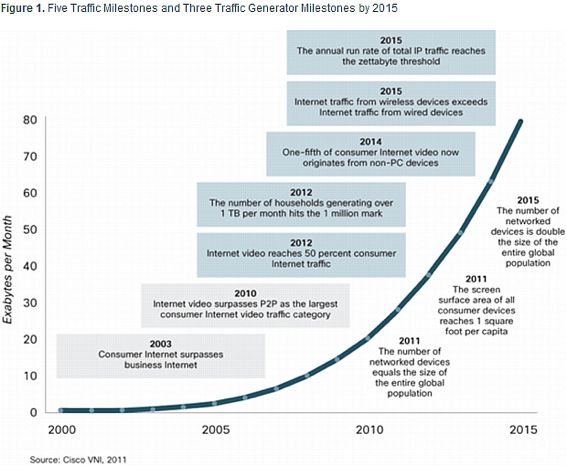
引用: THE TECH JOURNAL “Cisco Visual Networking Index Forecast”
*Exabyte=260 bit
インターネットのトラフィックの量も指数関数的に増えています。僕が2000年くらいに中学の同級生に会って、「最近、インターネットを覚えた」と言うと、「インターネットあったって何も使うことないじゃん、何を調べるの?」という冷たい反応でした。それがいま、ものすごい勢いで伸びています。こんなことは誰も予測していませんでした。単なるお遊びくらいにしか思っていなかったものが科学を変えて、私たちの生活も大きく変えています。インターネットもエクスポネンシャル・テクノロジーです。
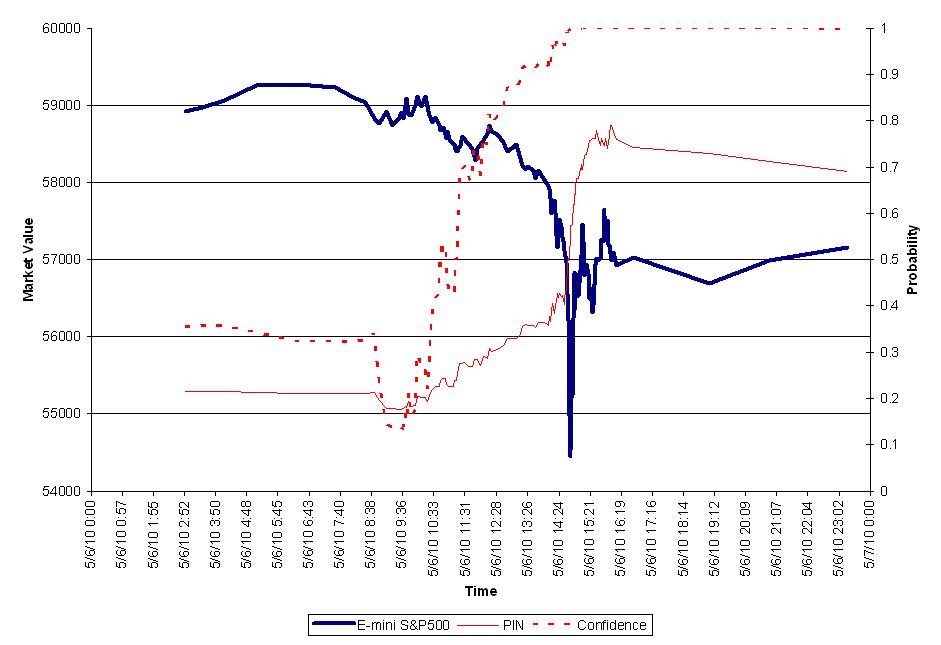
コンピュータ証券取引による株価暴落「Flash Crash 2010」
2010年のフラッシュクラッシュ
2010年5月6日に株価の急落「フラッシュ・クラッシュ」が発生しました。株取引をするコンピュータプログラムは0.01秒単位で売買しますが、そのプログラム同士が暴走して株価が暴落してしまった。これは、全く人間には手が付けられないエクスポネンシャル・テクノロジーの中の世界で起きたことです。このような現象が実際に起きはじめています。
この2010年にはアルバート・ラズロ・バラバシという、ネットワークモデルを提唱して有名な研究者ですが、今までの科学では考えられなかったような爆発的な情報量と爆発的な複雑さに対して、我々は全く無知で裸同然であるということを宣言しました。全くその通りで、僕が複雑系の研究を始めた1990年くらいの時は、データが少ないがゆえに想像力を豊かにして、小さいモデルから大きいモデルを考えた時代でした。しかし今はデータの世界の方が大きくて、相対的にモデルの提示できる世界が小さくなりました。現実の凄さや複雑さ、情報量の方が圧倒的で、理論の示す世界ががあまりにも貧弱に見えてしまう。それがインターネットとともに押し寄せてきて、「モデルや理論を見せるよりも現実を見たほうがいい」という世界が圧倒的になった。それが大学の構造や人々の科学に対する態度も変えています。
スピーチ・ホーム 赤ちゃんはどうやって言葉を覚えるか?

例えば、デブ・ロイというMITの研究者は自分の息子が生まれたとき、部屋の中に11個のカメラと13個のマイクを付けて、3年間ずっと彼を記録し続けることで、人がどうやって言葉を獲得するかを研究しました。それまで人の言語獲得に関する研究では、主観的な観察をベースにするしかなかったのですが、膨大なデータを元に解析したらどうなるのか? 図のように、お父さんが歩いた軌跡を緑色に、子どもを赤色に、一番よく会った場所を黄色で表示し、これらの行動パターンが言葉の獲得にどのような影響を与えるかを解析しました。
おもしろいのは、お父さんが子どもに「これはボールだよ」と教えてリビングルームを出て行ったあと、子どもがボールで遊んで、だんだん言葉と運動とのマッピングが行われて、そしてある時、「ボール」という言葉を喋ったそうです。彼はこの研究に「スピーチ・ホーム・プロジェクト」と名付けて、言語の獲得は子どもの頭の中だけで起きているのではなく、子どもと両親、家の構造など全ての要素を合わせたものが言語獲得装置であるという主張をしました。この例も、理論ではなく爆発的なデータを元につくられてくるエクスポネンシャル・テクノロジーのかたちです。
ヒューマン・ブレイン・プロジェクト 人の脳をコンピュータに移植する
「人の脳」が入るスーパーコンピュータ
スイスでは人の脳をまるごとコンピュータに入れてしまおうというプロジェクトが動いています。まず人の脳の前に猫の10億個の神経細胞をコンピュータに入れてシミュレーションすることから始まったのですが、当時多くの研究者が批判したのはその結合がランダムであるということでした。神経細胞同士の結合は必ず構造を成していて、その構造に猫らしさがあり、ランダムにしたら意味が無いという主張です。しかしよく考えると、たくさんのコンピュータに猫の神経細胞を分散して置くと、それらが猫の脳というひとつのシステムとして機能するように情報をやり取りしながら動くようにコンピュータのアーキテクチャをつくらなければならない。そこに秘密があるわけです。
つまりそこで思ったのは、猫らしさをつくるのではなくて、データが矛盾なく回るようアーキテクチャを作るということが、結果的に猫の主体性をつくるということに近づくのではないかということです。主体性というのは、昔の哲学者が考えたように誰にも触れられない個人の認識というようなものではなく、無矛盾につくられたコンピュータの中の、データのアーキテクチャの形と等しいかもしれない。それが、今グーグルやインターネットなど、様々なところで見られている特徴です。何かをつくろうとするのではなくて、その背後にあるものをつくることによって、当初つくりたかったものが現れてくる。そういうことが起こっているのではないでしょうか。
このように、エクスポネンシャル・テクノロジーというものがあり、それが爆発的に増えていくと、科学もいままでと同じ形でいられません。やれることも変わるし、「わかり方」も変えていかなくてはならない。そのとき、ただ混乱して騒ぐだけなのか、それとも、何ができるかを考えて科学の形を変えようとするか。僕は後者を考えていて、今までやってきたことは捨てて、新しい科学がつくれるのではないかということを目指しています。
ルービック・キューブを全数探索で解く
多くの場合、人工知能がベースにしているのは機械学習(Machine Learning) です。例えばルービックキューブには4325京(10の32乗)以上の組合せがありますが、それを最低何手で色を揃えられるか、研究者たちが数学の理論を使って、人間の頭で考えていた時代がありました。その後2010年にグーグルのエンジニアやプログラマのチームが、空いた時間に1000台コンピュータを回して総調べしました。すると、20回まわせばどんなパターンでも解けるということが分かり、非常に衝撃を受けました。人間にはもう理解できないアルゴリズムで、コンピュータを使うとやっと解ける。人間は最初に上の面を揃えて、その後に角を揃えて、と経験的に分かるやり方で解こうとします。しかし、必ずしも人間に分かるパターンが正解とは限らない。人間が理解できるかどうかに意味はなく、理解できないところに「神のアルゴリズム」の20手が存在しているわけです。このような認識がこれからは大事になると思います。
Deep Learning
また、この4〜5年で「ディープラーニング(深層学習)」という新しい技術が出てきました。人間の脳の神経細胞を模したネットワークにデータを大量に入力して、何が認識できるかを探ろうという試みです。これを考えたのはジェフリー・ヒントンという科学者です。彼は90年代に「階層型」という神経細胞のネットワークというのを考えました。その後その研究が廃れても、20年以上研究し続けて、実用化されたのが2007年。今ウェブサービス上にはこのディープラーニングを使ったものが続々と出現しています。グーグルはヒントンの研究室をまるごと大学から買い取りました。そしてこの技術を応用して、YouTubeから取ってきた何億枚もの画像データをあるアルゴリズムにかけると、何と猫の顔だけに反応する神経細胞が生まれた。コンピュータが自分で学習して猫の顔を認識できたということです。
コンピュータが認識した猫の顔
→[Part2] Rather than make the intellect, and continues to make a lifeこの猫の顔のニュースが発表されたとき、グーグルは企業秘密としてその方法を公開しませんでした。通常、アカデミックな世界では新しい発見があると論文にとして公開されますが、グーグルはそれをしません。(これはノウハウも含めて全部という意味で、この猫の画像の論文自体は出版されています)。これは別の意味で怖くて、新しい技術がブラックボックス化されていく。このことは、科学を語る上でもう1つの重要なキーワードです。なぜ飛行機が飛べるか、なぜコンピュータ動くか、ちゃんと説明できる人はなかなかいません。科学というのは、魔法であり、ブラックボックス化しいていく手続きなのです。「なぜかわからないけどできちゃう」というものが出てくる。そこがデータ駆動型の新しい科学の特徴であり問題点です。
SHARE